

Ijraset Journal For Research in Applied Science and Engineering Technology
An Enhanced and Adaptive Proximity Measure Algorithm for the Screening of Fake and Clone Social-Media Profiles
Authors: Sneha Mylabattula, Dr. P. Srinivasulu , Dr. P. Vamsi Krishna Raja
DOI Link: https://doi.org/10.22214/ijraset.2023.54970
Certificate: View Certificate
Abstract
The term \"semantics\" has been brought up in a broad range of text mining studies due to the significant role that text semantics plays in establishing the meaning of a document. On the other hand, there is a dearth of research that synthesises the several subfields of research and offers a synopsis of the works that have been produced. This paper gives an in-depth mapping of research that focuses on semantics and text mining. In order to produce an accurate map, the researchers followed a regimented set of protocols throughout their work. The results were gleaned from a total of 1693 pieces of study that were selected from a pool of 3984 publications that were housed in five different online libraries. Academics who are working on semantics-focused text mining may find the mapping that was generated to be useful as a reference. The mapping gives a fundamental overview of the subject matter, pinpoints certain places that need the construction of primary or secondary studies, and identifies particular regions in need of the creation of either. It shows that the processing of semantic components in text mining is still an open research issue even though various studies have been developed despite the fact that these studies have been established.
Introduction
I. INTRODUCTION
People that participate in social networking endeavour to write about their feelings, daily happenings, opinions, ideas, and news, in addition to writing about day-to-day activities such as travelling, drinking, and eating. Users that are malevolent or who have clone accounts look at every profile, assess the activities of other users by studying their profiles, timeline messages, and tweets, and then publish disparaging remarks about the people who really established the accounts they are impersonating. Users that are not who they claim to be distribute false news stories, links to images that have been altered, and other similar content. A significant portion of the people who participate in online social networks (OSNs) are oblivious to the fake profiles and accounts that are accepting their friend requests and masquerading as them, which creates issues for the individuals who really have their real identities online.
Over the course of the last several years, OSNs such as Facebook, Twitter, and Instagram have made it simpler for their millions of users to make use of their respective platforms. People utilise these platforms to communicate with friends, family, and even those who are absent, as well as to share their interests, thoughts, and other information that is pertinent to society, politics, and other themes. Some OSNs enable users to communicate with one another via the exchange of messages; these messages are limited in length, much like tweets on Twitter, to a predetermined number of characters. Twitter users were only able to post one tweet at a time that was up to 160 characters long. There are now 340 million users using Twitter throughout the world.
There are a lot of people in the modern world that are recognised as spammers, but they are also known as destructive users or phoney users. Spammers are only one of these names. Because they spread false information, participate in bullying and personal harassment, and rob bank accounts by using harmful links, these individuals are accountable for a significant portion of the confusion that might arise amongst users. It is of the greatest need to put a stop to all of these fraudulent user activities, and in order to detect phoney accounts, a tool that is both powerful and dynamic is required. It is of the utmost importance to put an end to all of these fraudulent user actions.
A large variety of different approaches to machine learning have been developed in order to identify cloned and fraudulent profiles and to generate predictions about them. Cloned profiles are ones that have been created by hackers and have the same name and profile photos as the original profile. Cloned profiles may be distinguished from original profiles by their lack of attribution. For the purpose of detecting counterfeit or cloned profiles, a brand new method referred to as the dynamic distance measure has been developed within the scope of this study. The linear SVC is used in the proposed method, which has the ability to boost accuracy while concurrently lowering the error rate. Both of these outcomes are desirable.
II. LITERATURE REVIEW
A fresh method for determining whether or not fraudulent clone profiles are real was developed by Georgios Kontaxis and his fellow researchers [2]. We examine the clone profiles that were produced by the OSN user in addition to retrieving the data from the client profiles. The score of the user profile is compared with the similarity score that describes the false and clone predictions. The clone profiles are confirmed depending on whether or not they match the score of the user profile. If the score of similarity between the two profiles is very high, then the profile in issue is known as a fake profile or a clone profile.
Two novel approaches to distinguishing cloned profiles from other profiles were proposed by Brodka and colleagues [3]. The main strategy is defined by the degree of similarity between the distinctive esteems of the original and cloned profiles, while the secondary strategy is based on the connections that exist inside the organisation. A random selection will be made to determine who the victim will be, and that person will be the one who raises questions about whether or not his identity has been reproduced. After that, an inquiry search is carried out using the person's name as the main key in order to seek for profiles that have the same name as the person who was killed or wounded. This search is done in order to hunt for people who have the same name as the person who was killed or injured.
Cresci S et al., [4] established the brand-new and one-of-a-kind technology that makes it easy to detect fraudulent and cloned accounts from the different Twitter data repositories. This makes it possible for users to easily spot fake accounts and accounts that have been copied. The standards and regulations will serve as the deciding factor in the organisation of the dataset. Quite a few different machine learning techniques are used to this dataset in order to carry out an exceptionally precise search for fraudulent records and records that have been copied. In light of the classifier that was selected, the classifier that was shown functions quite well.
In order to differentiate real records on Twitter from bogus ones, a technique of characterization that goes by the name "Ahmed El Azab et al., [5]" has been given. In the first step of the procedure, they have gone through the many investigations, sorted, and weighted the findings, and have come to a conclusion. They have compiled a number of noteworthy highlights for the recognition interaction. Numerous studies are being conducted with the goal of identifying the fewest possible features that must be present for correct findings to be obtained. Out of a total of 22 ascribes, only seven credits were chosen since these seven are the only ones that can effectively identify false records and have utilised these components to characterise approaches. An analysis of the sequence of processes that are dependent on the findings is carried out, and the one that yields the most precise result is chosen as the best option.
III. METHODOLOGY
SVC is a nonparametric clustering method, which means that it does not make any assumptions regarding the number of clusters present in the data or the structure of those clusters. This allows it to provide more accurate results than other clustering methods. Because of our prior experiences, we've discovered that it operates most effectively with low-dimensional data; as a result, if the dimensions of your data are vast, a preprocessing step—such as making use of principal component analysis—is often required. Based on our previous experiences, we've found that it performs most effectively with low-dimensional data. A Linear SVC, which is also known as a Support Vector Classifier, is designed to adapt to the information that you provide it in order to build a hyperplane that is the "best fit" for splitting or categorising your data. This is the primary objective of this kind of classification algorithm. As soon as you have the hyperplane, the next thing you need to do is feed some features into your classifier so that it can decide what the "predicted" class will be. In this particular instance, the use of Matplotlib is not at all necessary for the execution of Linear SVC. In this location, we are practising with it in order to be ready for the data visualisation that will ultimately take place. In the majority of situations, you will not be able to visualise as many dimensions as you will have features. Despite this, it is essential to visualise linear svc at least once in order to have a knowledge of how it functions. In order to convert arrays, all that will be required of you is to import svm from sklearn and numpy. This is due to the fact that the visualisation packages that we are using already have an installation completed.
In order to carry out classification, the Linear Support Vector Classifier (SVC) method uses a linear kernel function. This method yields good results when applied to datasets that include fraudulent Twitter accounts. When compared to the SVC model, the Linear SVC adds additional parameters such as penalty normalisation, which may apply either 'L1' or 'L2', and a loss function. These parameters are in addition to the SVC model's standard set of parameters. The kernel method cannot be changed in any manner since linear SVC is based on the kernel linear method, which is the foundation of the kernel method.
Getting Ready to Present the Data Teaching the Model How to Make Predictions and Evaluating Whether or Not They Are Correct Putting an Example of Classification to Use with a Makebelieve Profile Dataset
The data flowchart functions as the engine that propels the important designing equipment forward. The purpose of this design is to acquaint users with the fundamentals of the system. The structure method, the data employed by method, the partner outside substance that interacts with the framework, and ultimately the data streams that occur within the framework make up these components.
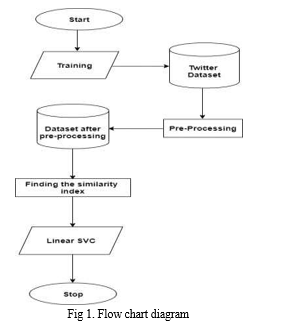
IV. ROBUST DATA PREPROCESSING
The programmer’s entire name is likewise named Matrix Laboratory; the term "Matrix Laboratory" is just a shortened version of the programme's full name. This is a highly important step in machine learning that helps to process the dataset by removing the missing values and irrelevant data from the dataset, followed by the extraction of the accurate and helpful data from the dataset. This phase is extremely important. This phase is very important in the process. The raw data that are included in the Twitter Fake Profile dataset, which was obtained via Kaggle, are cleaned up using the pre-processing method. This provides a better platform for training models and is utilised in the dataset including Twitter fake profiles. At this point, the data are changed into a format that is not only easier to comprehend but also more favourable to being read by the algorithms. Not only is this format more intelligible, but it is also easier to read.
The use of certain transformation techniques to the initial data might potentially provide useful outcomes for the binning process. The standardization method is a technique that is used widely for a number of machine learning algorithms in order to address the problem of heterogeneous data distributions. This is because the standardization method allows for the data to be transformed into a uniform format. Before binning, other techniques of transforming data are investigated, including the Quantile Transformation (QTF), the Min Max Scaler (MMS), and logarithmic computation scalers. In these evaluations, the Quantile Transformation algorithm is used with the EQW approach in order to carry out the tests. QTF is a pre-processing approach that is considered as being extremely dependable. This is due to the fact that it is able to reduce the influence that outliers in false profile datasets have on the results.


Conclusion
For the objective of this investigation, Linear Support Vector Machines are used in order to do analysis on the data obtained from Twitter accounts. This work was able to address the challenge of identifying bogus accounts on Twitter by making use of a linear support vector machine. In order to verify the results of the study, a substantial amount of testing was carried out making use of cosine similarity functions in a variety of different configurations. The findings of the research indicate that using Linear SVM in the process of spotting phoney accounts gives favourable results, as can be seen from the conclusions derived from the analysis of the data. These findings were reached after the studies were completed. The fact that this will disclose the extremely complex correlations that already exist among the data without requiring any alterations to be made is one more strong argument in favour of adopting Linear SVM. This is an additional argument that may be used in favour of utilising Linear SVM. This is a compelling argument since it is one of the reasons why using Linear SVM comes with such a high level of recommendation. This algorithm can provide more accurate results and has a greater capacity to deal with both simple and complex datasets. It also has a bigger ability to handle larger amounts of data. In addition to this, it can handle larger and smaller quantities of data with equal ease.
References
[1] S. Venkatesan, M. Albanese, A. Shah, R. Ganesan, and S. Jajodia, \"Detecting stealthy botnets in a resourceconstrained environment using reinforcement learning,\" in Proc. Workshop Moving Target Defence, 2017, pp. 75_85. [2] M. H. Arif, J. Li, M. Iqbal,and K. Liu, \'\'Sentiment analysis and spam detection in short informal text using learning classifier systems,\'\' in Soft Computing. Berlin, Germany: Springer, 2017, pp. 1_11. [3] Piotr Brodka, Mateusz Sobas and Henric Johnson, \'\'Profile Cloning Detection in Social Networks\'\', 2014 European Network Intelligence Conference [4] Stefano Cresci, Roberto Di Pietro, Marinella Petrocchi, Angello Spognardi, Maurizio Tesconi, \'\'Fame for sale: Efficient detection of fake Twitter followers\'\', 2015 Elsevier’s journal Decision Support Systems,Volume 80. [5] Sever Nasim, Mehwish, Andrew Nguyen, Nick Lothian, Robert Cope, and Lewis Mitchell. \"Real-time detection of content polluters in partially observable Twitter networks.\" arXiv preprint arXiv:1804.01235 (2018). [6] K. Patel, S. Agrahari and S. Srivastava, \"Survey on Fake Profile Detection on Social Sites by Using Machine Learning Algorithm,\" 2020 8th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), 2020, pp. 1236-1240. [7] Sowmya P and Madhumita Chatterjee, \'\'Detection of Fake and Cloned Profiles in Online Social Networks\'\', Proceedings 2019: Conference on Technologies for Future Cities (CTFC) [8] Georgios Kontaxis, Iasonas Polakis, Sotiris Ioannidis and Evangelos P. Markatos, \'\'Detecting Social Network Profile Cloning\'\', 2013. F-Measure Accuracy Recall Precision 0 10 20 30 40 50 60 70 80 90 CDSim C 4.5 Linear SVC F-Measure Accuracy Recall Precision © 2021 JETIR September 2021, Volume 8, Issue [9] M. H. Arif, J. Li, M. Iqbal,and K. Liu, \'\'Sentiment analysis and spam detection in short informal text using learning classifier systems,\'\' in Soft Computing. Berlin, Germany: Springer, 2017, pp. 1_11. [10] S. D. Munoz and E. Paul Guillen Pinto, \"A dataset for the detection of fake profiles on social networking services,\" 2020 International Conference on Computational Science and Computational Intelligence (CSCI), 2020, pp. 230-237. [11] Goswami, A., Kumar, A. Challenges in the Analysis of Online Social Networks: A Data Collection Tool Perspective. Wireless Pers Commun 97, 4015–4061 (2017). [12] M. Smruthi and N. Harini, \"A Hybrid Scheme for Detecting Fake Accounts in Facebook\", International Journal of Recent Technology and Engineering (IJRTE), vol. 7, no. 5S3, February 2019. [13] P. Tehlan, R. Madaan and K. K. Bhatia, \"A Spam Detection Mechanism in Social Media using Soft Computing,\" 2019 6th International Conference on Computing for Sustainable Global Development (InaCom), 2019, pp. 950-955.
Copyright
Copyright © 2023 Sneha Mylabattula, Dr. P. Srinivasulu , Dr. P. Vamsi Krishna Raja . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET54970
Publish Date : 2023-07-24
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online